用Python来写各种各样的排序算法 (Part.3)
O(n Log(n))系列
接下来是O(nlog n)组别的三个主力: 堆排序 归并排序 快速排序
¶堆排序 Heap Sort
堆是一种数据结构,我们这里要用的是二叉堆。数据可以表现成一颗二叉树,通过对树的节点修改,完成排序操作。
一个数据为[1,2,3,4,5,6,7,8,9,10,11,12,13]的树长这样
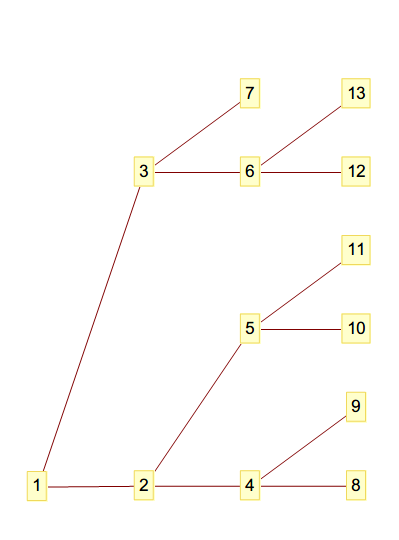
从下到上从左到右观察序号,可以总结出来(当然也可以直接通过计算)
- 第i列有2^(n-1)个数字
- 父节点在 2*i 的位置 或者说
int((i - 1)/2)的位置 - 左子节点在 2*i + 1
- 右子节点在 2*i + 2
为了排序我们规定左(下)子节点的数据大小永远小于等于右(上)子节点,同时父节点不大于子节点。 获取排序结果的时候只要从左到右从下到上读取这棵树就行。
要进行排序 我们需要做的就是对这些节点进行旋转,术语叫做最大堆调整

但是不能想当然地直接交换父节点和子节点的顺序,这在最后一块虽然是没问题的,但是如图 在中间的话,交换之后 子节点的顺序就出现了错误。
为了完成修改顺序,就需要一层一层向父节点走上去,把小的数字一层一层向上放到父节点,大数字放在子节点上
data = [1, 4, 3, 9, 5, 6, 7, 8, 2, 10, 11, 12, 13]
# 创建最大堆
def max_heap(start, end):
root = start # 根节点位置
end = end # 最后的位置
while True:
child = 2 * root + 1 # 二叉子节点开始的位置
if child > end: break
# 先比较两个子节点,选择更大的一个child
if child + 1 <= end and data[child] > data[child + 1]:
child += 1
if data[root] > data[child]:
data[root], data[child] = data[child], data[root]
root = child # 继续向下
else: # 子节点小于根节点,跳出
break
for start in range((len(data) - 2) // 2, -1, -1):
end = len(data) - 1 # length - 1: 保证有两个位置,不越界
max_heap(start, end)for循环从最下面一层的父节点 也就是从右向左第二列开始,先交换9 2 8那组,把2和9的数据交换了位置, 接下来从右向左第三列,将4 5 2(9)的顺序摆正,完成了二叉树的排序
虽然排序完成之后的结果是我们期望的,那是因为第一个数字和最小的数字都是1
如果用我们的随机生成器生成一个丢进来,[3, 5, 4, 8, 2, 7, 6, 0, 9, 1]可能会得到这样的结果[0, 1, 4, 5, 2, 7, 6, 8, 9, 3]还需要进一步处理。
不过之前的操作结果很明显,最小的数字到了最上面,这时候只要将第一个数字和最后一个没有确定顺序的数字交换就行 由于还没有排序结果,就把第一个和最后一个数字交换
for end in range(len(data) - 1, 0, -1):
data[0], data[end] = data[end], data[0]
max_heap(0, end - 1)就能获得从大到小的排序结果了
调用函数: heap_sort
输入:
[3, 5, 4, 8, 2, 7, 6, 0, 9, 1]
第一部分:
[3, 5, 4, 8, 1, 7, 6, 0, 9, 2]
[3, 5, 4, 0, 1, 7, 6, 8, 9, 2]
[3, 5, 4, 0, 1, 7, 6, 8, 9, 2]
[3, 0, 4, 5, 1, 7, 6, 8, 9, 2]
[0, 1, 4, 5, 2, 7, 6, 8, 9, 3]
第二部分:
[1, 2, 4, 5, 3, 7, 6, 8, 9, 0]
[2, 3, 4, 5, 9, 7, 6, 8, 1, 0]
[3, 5, 4, 8, 9, 7, 6, 2, 1, 0]
[4, 5, 6, 8, 9, 7, 3, 2, 1, 0]
[5, 7, 6, 8, 9, 4, 3, 2, 1, 0]
[6, 7, 9, 8, 5, 4, 3, 2, 1, 0]
[7, 8, 9, 6, 5, 4, 3, 2, 1, 0]
[8, 9, 7, 6, 5, 4, 3, 2, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
0.00017581405477187906s10个数字的排序的速度看不出什么,那么就进行100000个数据吧
调用函数: heap_sort
1.2504024981660005 (第1次)
1.2336180569066364 (第2次)
1.244385105961435 (第3次)
1.2345189923802011 (第4次)
1.2370223346321563 (第5次)
--------------------------------------------------------------------------------
执行时间: 6.199946988046429 (共5次)
平均时间: 1.239989397609286
最好: 1.2336180569066364
最差: 1.2504024981660005
================================================================================不必多说地相比O(n^2)的性能爆炸
¶归并排序 Merge Sort
程序设计的一条重要思维就是大事化小 小事化了 其实就是把大问题分割为一个个小的问题,处理了这些小问题就等于解决了大问题。
归并排序就是基于这一思维的,而且能够很好地用于多线程处理。
归并排序的思想也是出奇地简单:
- 把数据一分为二
- 把一分为二的部分继续细分
- 如果一组只剩下一个或两个数据,则排序并返回上一层
当最后一层退出之后,得到的就是排序完成的数据了!
这需要意会 对方想不出该说什么,直接朝你丢出了代码
def merge_sort(data):
"""Merge sort ver.recursive
归并排序,递归调用
Args:
data (List[int]): list to sort, need a not None list
Returns:
List[int]: ordered list
"""
length = len(data)
def merge(_left, _right):
if _left == _right:
return
# 先分治
mid = (_left + _right) // 2 # 对半分
# 再调用自身排序
merge(_left, mid)
merge(mid + 1, _right)
# 交换顺序错了的两个元素
if _right - _left == 1 and data[_left] < data[_right]:
data[_left], data[_right] = data[_right], data[_left]
temp = [] # 合并操作的临时列表
left_side = _left # 左半边指针
right_side = mid + 1 # 右半边指针
# 进行合并
# [_left, mid] [mid + 1, _right] 分治的左右范围
# [left_side, mid] [right_side, _right] 合并操作时的范围
while left_side <= mid and right_side <= _right:
if data[left_side] >= data[right_side]: # 左边元素更大
temp += [data[left_side]]
left_side += 1
else:
temp += [data[right_side]] # 右边元素更大
right_side += 1
while left_side <= mid: # 左半边还有剩余元素
temp += [data[left_side]]
left_side += 1
while right_side <= _right: # 右半边还有剩余元素
temp += [data[right_side]]
right_side += 1
data[_left:_right + 1] = temp # 切片操作范围 [_left, _right + 1)
merge(0, length - 1) # 开始排序
return data主要的难点是在控制和记录每一层的左右范围,这里我使用了left_side 和right_side两个变量来记录左右范围。 程序一层一层通过调用自身,缩小范围,直到只剩下一个或者两个元素在一组里,这是我们期望的最容易排序的情况。开辟一个新空间,存放排序好的这部分元素,在覆盖回这部分的里(left_side和right_side范围)。一层一层下去上来,效率极高而且数据量大的话可以分配到多线程来处理。
数据测试同样拿[3, 5, 4, 8, 2, 7, 6, 0, 9, 1]进行:
调用函数: merge_sort
[5, 3, 4, 8, 2, 7, 6, 0, 9, 1]
[5, 4, 3, 8, 2, 7, 6, 0, 9, 1]
[5, 4, 3, 8, 2, 7, 6, 0, 9, 1]
[8, 5, 4, 3, 2, 7, 6, 0, 9, 1]
[8, 5, 4, 3, 2, 7, 6, 0, 9, 1]
[8, 5, 4, 3, 2, 7, 6, 0, 9, 1]
[8, 5, 4, 3, 2, 7, 6, 0, 9, 1]
[8, 5, 4, 3, 2, 9, 7, 6, 1, 0]
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
输入长度: 10 循环次数: 48 比较次数: 28 操作次数: 35需要开辟新空间进行合并的操作导致了这种算法需要额外一倍的空间。但是速度很可观,100000元素只需要1s不到的时间!
调用函数: merge_sort
0.9027587511724603 (第1次)
0.9062107599506295 (第2次)
0.9047141160206942 (第3次)
0.9057230343050069 (第4次)
0.9114704325809653 (第5次)
--------------------------------------------------------------------------------
执行时间: 4.530877094029757 (共5次)
平均时间: 0.9061754188059513
最好: 0.9027587511724603
最差: 0.9114704325809653
================================================================================如果加上多线程,性能想必就会更高了了!
¶快速排序 Quick Sort
这是一种十分简单的算法,简单带来了代码的清晰与高效。通过递归调用达到O(nlog n)的性能。
def quick_sort(data):
"""Quick sort
递归解决列表排序,使用局部变量加快访问,列表推倒式简单方便,可能效率不如原生的。
没有使用迭代的方式,因为测试之后发现效率更低。
Args:
data (List[int]): list to sort, need a not None list
Returns:
List[int]: ordered list
"""
def _quick_sort(_data):
if len(_data) <= 1: return _data
pivot = _data[0]
left = _quick_sort([x for x in _data[1:] if x <= pivot])
right = _quick_sort([x for x in _data[1:] if x > pivot])
return right + [pivot] + left
return _quick_sort(data)pivot就是以第一个元素取的基准,将第一个元素后面的,大于基准的放到基准左边,小于的放到右边,一层粗略的排序就完成了。继续重复操作。不过记住,这些都是从元素最少的一层层上来变大的。
简洁带来的提升十分了不得,100000元素的测试比上面两个快了一倍!
调用函数: quick_sort
0.43976878323830193 (第1次)
0.4490810856157079 (第2次)
0.4438049026021257 (第3次)
0.43707580586288164 (第4次)
0.4395657501470318 (第5次)
--------------------------------------------------------------------------------
执行时间: 2.209296327466049 (共5次)
平均时间: 0.4418592654932098
最好: 0.43707580586288164
最差: 0.4490810856157079
================================================================================总结
对比O(nlog n)和O(n^2),很明显的不同就是前者多用递归,后者循环搞定。
而递归的好处便是每次需要对比的次数虽然是指数增长的,但也是从少到多,同时数量少的次数最多。
或者换种说法,把任务分成了许许多多小任务,增加了速度。
我们来看看1000000(1M)个元素的排序情况:
| 调用函数 | heap_sort | merge_sort | quick_sort | build_in_sort |
|---|---|---|---|---|
| 第1次 | 15.538451790127148 | 10.874872713869692 | 6.393853407430754 | 0.7502603732060575 |
| 第2次 | 15.855851413690411 | 10.857533241648653 | 6.189114391967195 | 0.7355045528497367 |
| 第3次 | 15.471093442522005 | 10.87834212548428 | 6.152806720529185 | 0.7365906683313892 |
| 第4次 | 15.276213356989288 | 10.89595602704847 | 6.206629677458523 | 0.7408338368256513 |
| 第5次 | 15.331094317126087 | 10.845189722152554 | 6.193406199158062 | 0.750332662 |
| 执行时间 | 77.47270432 | 54.35189383020365 | 31.135810396543718 | 3.7135220931239163 |
| 平均时间 | 15.494540864090988 | 10.87037876604073 | 6.227162079308743 | 0.7427044186247833 |
| 最好 | 15.27621336 | 10.84518972 | 6.152806721 | 0.735504553 |
| 最差 | 15.85585141 | 10.89595603 | 6.393853407 | 0.750332662 |
虽然从左到右一个比一个快了,但还是被内建函数以数量级的区分度碾压···